
Last year, I published an analysis of AI risk, emphasizing divergent expert opinion, high uncertainty, algorithmic reasons to be less concerned about AI takeover catastrophe, and a strategy focused on redirecting AI companies away from danger and toward the public good. While much has happened in AI over the past year, these core conclusions largely still hold up, though not entirely, as detailed below.
This year, I would emphasize two core themes:
On AI risk, there is continued uncertainty and divergent expert opinion, especially about the prospect of takeover catastrophe. My own view of the risk has become more nuanced, though that hasn’t substantially shifted my general skepticism of near-term takeover catastrophe. But, we are one year closer to finding out.
On AI strategy, now is a moment to advance a range of activities in preparation for a US domestic policy fight if and when we have a change of government, and for international negotiation, especially with China, which also probably requires a US change of government.
Note: by AI takeover catastrophe, I mean scenarios in which AI takes over the world and either kills everyone or causes some other form of catastrophe. This has long been my primary focus within the AI risk space due to the extremely high stakes, though there are also other important AI scenarios, including other catastrophe scenarios. My longstanding and ongoing position is that it’s important to address the full range of high-consequence effects of AI, including effects that are already occurring.
Risk
“Jagged.” That is the word used by the International AI Safety Report (IAISR) 2026 to describe recent changes in AI capability. There have been substantial capability increases, especially in quantitative domains, but major limitations remain. That is consistent with my own read of the current AI landscape. I think this projects to low risk of takeover catastrophe from the current AI paradigm of large language models (LLMs) and related generative AI systems, but there is some uncertainty about this.
For example, academic researchers (1, 2, 3, 4, 5, 6, 7) find that current AI systems can inform or even automate significant chunks of the research process, especially for quantitative, computer-based research, but the AI systems struggle more with judgment on what topics make for important research, and they are unsuitable for work involving a physical and human presence, such as field work and ethnography. There are concerns that this may inundate research communities with a flood of mediocre papers, resulting in more publishing output but less intellectual progress.
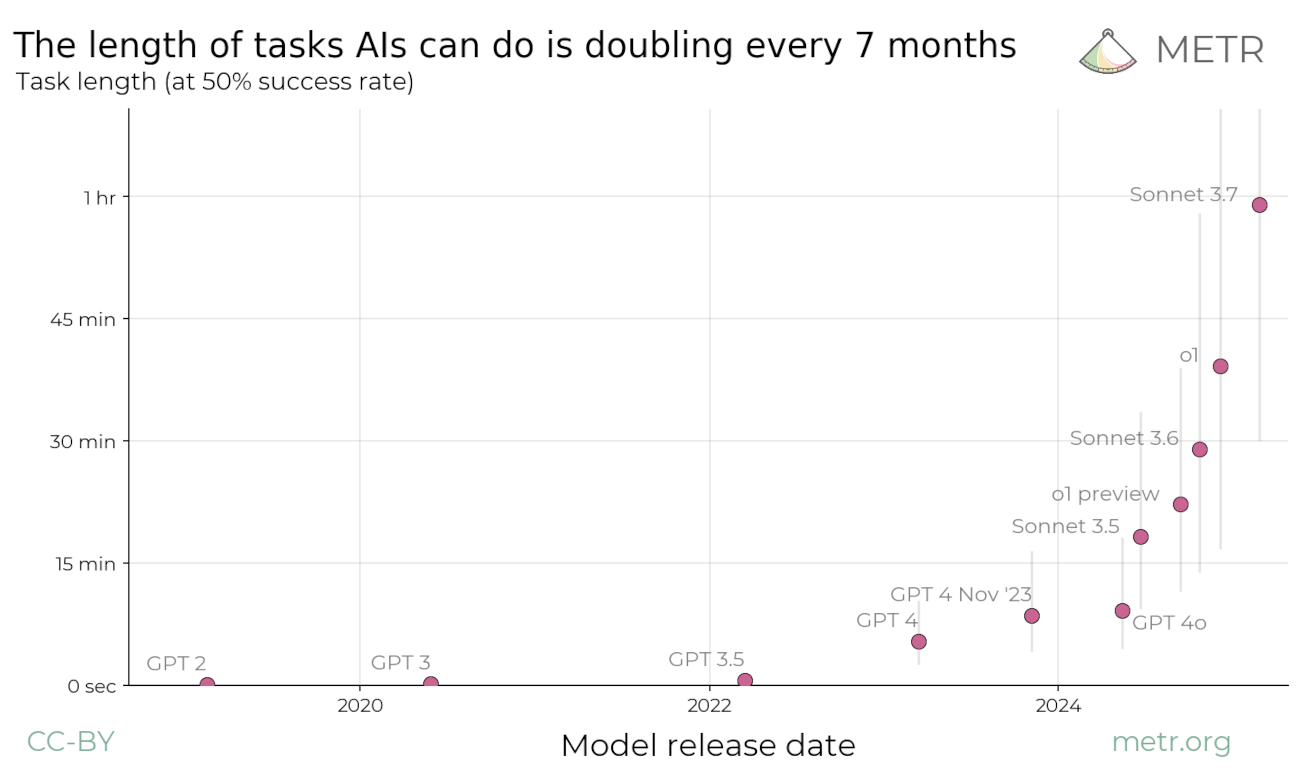
Macro trends in AI also paint a mixed picture. The much-discussed “METR graph” portrays exponential growth in AI software task completion as measured in how long it takes humans to complete the task, but it has been criticized for weak methodology and narrow scope (software only). METR found substantially less growth in AI self-driving. Additionally, analysis of the METR software data finds that AI systems manage errors less well than humans, and that error management has not improved in more recent AI systems. Other work finds only minor progress in AI system reliability, of relevance for the automation of critical systems. Finally, analysis of RL scaling and METR data finds major cost concerns, suggesting that significant advancements beyond the status quo may be cost-prohibitive.
Meanwhile, the economics of LLMs are sufficiently tenuous that the current AI boom may be a giant market bubble. Much of the enthusiasm about LLMs comes from increasing the scale of AI systems, but larger scale means larger costs. Political opposition, such as to data centers, also increases costs, as do supply shocks from the Iran war. These factors further reduce near-term risk from large AI systems.
Research on how AI systems work also shows mixed signs. An important distinction is between memorizing scattered facts and forming coherent conceptual understandings. My 2025 AI risk article highlighted the “bags of heuristics” theory, which posts that LLMs consist of scattered facts. However, I had overlooked the phenomenon of grokking, in which an AI system, if trained for long enough, eventually shifts from scattered facts to conceptual understanding. Recent research finds that LLMs may form a motley mix of mechanisms, including both heuristics and grokked understanding. Other research on scenario cognition and the fractured entangled representation hypothesis suggest that LLMs may consist mainly of scattered fact memorization, and that as LLMs scale to larger and larger sizes, they may tend to have more memorized facts and less conceptual understanding. Intuitively, it makes sense that larger model size could enable more memorization while making it harder to go through grokking to form conceptual understandings. So, while my 2025 article overlooked grokking, its general takeaway about the limitations of LLMs may still be basically correct.
AI researcher Melanie Mitchell recently wrote, “Something that baffles me about many AI researchers is the seeming lack of curiosity about the mechanisms underlying the benchmark performance they report.” I completely agree. She was referring to computer scientists, but I would add that AI risk and policy analysts also need to study how AI systems work. In my opinion, this has been a major failure of the interdisciplinary field of AI research.
A lot of attention does go to the often-flowery pronouncements by AI experts and industry executives. I put very little weight on this. As author of one of the first studies of AI expert forecasting and as a professional risk analyst, I know that expert judgment on future AI and similar topics is highly unreliable. Furthermore, industry executives have a colossal conflict of interest, with many billions of investment dollars dependent on their ability to project confidence.
Taking all of the above into account, I remain as doubtful as I was last year about the prospects of takeover catastrophe from future iterations of current LLM-based AI systems. However, there is a lot of uncertainty, so the risk cannot be dismissed entirely. Long-term, I am more concerned about AI work pursuing other paradigms, though these are difficult to project.
Strategy
While I am less concerned about extreme near-term AI risks, some other people are, to the point of describing a need to triage AI policy within the next year or so while something, anything can still be done. To that, I would ask: how?
Today, the most advanced AI systems are developed by US corporations. However, in the US right now, the fox is guarding the hen house. Guided by industry insiders, such as venture capitalist and White House AI czar David Sacks, the Trump administration is not just abstaining from advancing AI risk policy—it is actively working to prevent states from pursuing their own policies, first via proposed legislation in May 2025 and then via a December 2025 executive order. Congress killed the legislation following bipartisan outcry from state governors and the executive order is unlikely to survive legal challenges, but they both demonstrate a White House with less than zero appetite for substantial policy to address AI risks.
Several states have passed bipartisan policies addressing catastrophic AI risk, including California and New York. These play a constructive role, but they are limited. There are legal limits to what states can do, but the existing policies do not reach these limits. One apparent reason is aggressive AI industry lobbying.
The good news is that the AI industry is deeply unpopular across the US public. Energy-hungry data centers are driving up electricity prices and polluting surrounding neighborhoods while impeding progress on climate goals. Generative AI systems are being used to flood the internet with misinformation and slop, and they may be causing some unemployment (or not). The industry threatens to either further concentrate wealth and power within a narrow elite, or to collapse the economy if this is all just a market bubble, or perhaps both. This unpopularity helps to explain the bipartisan state policies.
Perhaps the Trump administration will change course, especially if AI becomes even more unpopular, but unfortunately, this seems unlikely. Absent such a shift, there will be no substantive US AI risk policy until, at the earliest, when a new administration enters the White House in 2029.
Meanwhile, it is important to build political power in support of AI risk policy alongside continued research on specific policy measures. This can include efforts to shift public opinion by drawing attention to the harms of AI, as well as projects to organize and mobilize the public, such as the Encode group. This can help to improve AI corporate governance even without federal policies, and it will make federal policy more politically feasible, whether under the current administration or some future one.
In my opinion, the project of building political power on AI risk should embrace the wider concerns about AI instead of focusing narrowly on takeover catastrophe. This would enable a larger and more powerful political coalition. It can also help to avoid a potential pitfall of AI catastrophe politics, in which raising alarm about AI fuels an “AI is powerful” narrative that counterproductively fuels investment in dangerous AI technology. This fits a broader pattern of risk narratives reinforcing technologist hype. Instead of getting caught in this dilemma, we start with the end-goal of robust AI risk policy and work backwards on how to build the political power needed to make it happen.
China
The US AI industry’s strongest argument against regulation is “but China”. The argument is that bad things will happen if China outcompetes the US on AI, and therefore the US must be willing to accept harms and take risks to ensure that we win and they lose. This argument follows the longstanding logic of a race to build advanced AI, especially if the race has winner-takes-all dynamics, such as for building a superintelligent AI system that takes over the world. However, that can be extremely risky, building extreme AI systems with limited safeguards.
The best course is for the US and China (and any other countries) to abandon reckless competition and instead cooperate to ensure that advanced AI systems are either built responsibly or not built at all. This requires diplomacy. The importance of international AI cooperation is one reason why I arranged the GCRI Symposium on World Peace, which studied prospects for avoiding war and improving relations between countries. It suggests a range of constructive opportunities, such as international expert dialog and responsible cosmopolitanism from national leaders.
India hosted the recent AI Impact Summit 2026 with the slogan बहुजन हिताय | बहुजन सुखाय, “sarvjan hitai, sarvjan sukhai”, “welfare for all, happiness of all”, an ancient Indian expression. This fits with my prior advocacy for a political ideology of democratic welfarism. The goal of advancing the general welfare can also be found in the Preamble to the US Constitution and in China’s Xi Jinping Thought (#8 of the 14 commitments). Perhaps it could serve as a basis for improved international relations, including on AI. That may facilitate agreement on whether or not to build advanced AI systems, and how to build and deploy them if we do, in order to prevent catastrophe and achieve good outcomes for the world.
Image credit: Seth Baum, showing a stylized depiction of several trends in AI (red: the “METR graph”, blue: cost analysis based on METR data, grey: error management)


{kind=link}